
在大模型普及的当下,很多人都遇到过两个核心痛点:一是大模型回答经常出现 “幻觉”,凭空捏造信息;二是无法让大模型精准调用自己的私有数据,比如个人读书笔记、产品手册、项目文档、行业资料。而 RAG(检索增强生成)技术,就是当下解决这两个问题、最易落地的 AI 技术,无需高额算力、无需复杂的模型微调,零基础也能快速上手。
一、1 分钟搞懂 RAG 核心逻辑
RAG 的核心逻辑可以拆解为 “检索 + 生成” 两步:先从用户的私有知识库中,检索出与用户问题高度相关的内容片段,再将这些内容与用户问题一起输入大模型,让大模型仅基于检索到的权威内容生成回答,从根源上杜绝幻觉,同时实现私有数据的精准调用。
相比大模型微调,RAG 有着不可替代的优势:成本极低,无需大量标注数据和高端算力;迭代灵活,新增 / 修改文档无需重新训练,实时生效;数据安全,私有数据无需上传给大模型训练厂商,适合个人与中小团队落地使用。
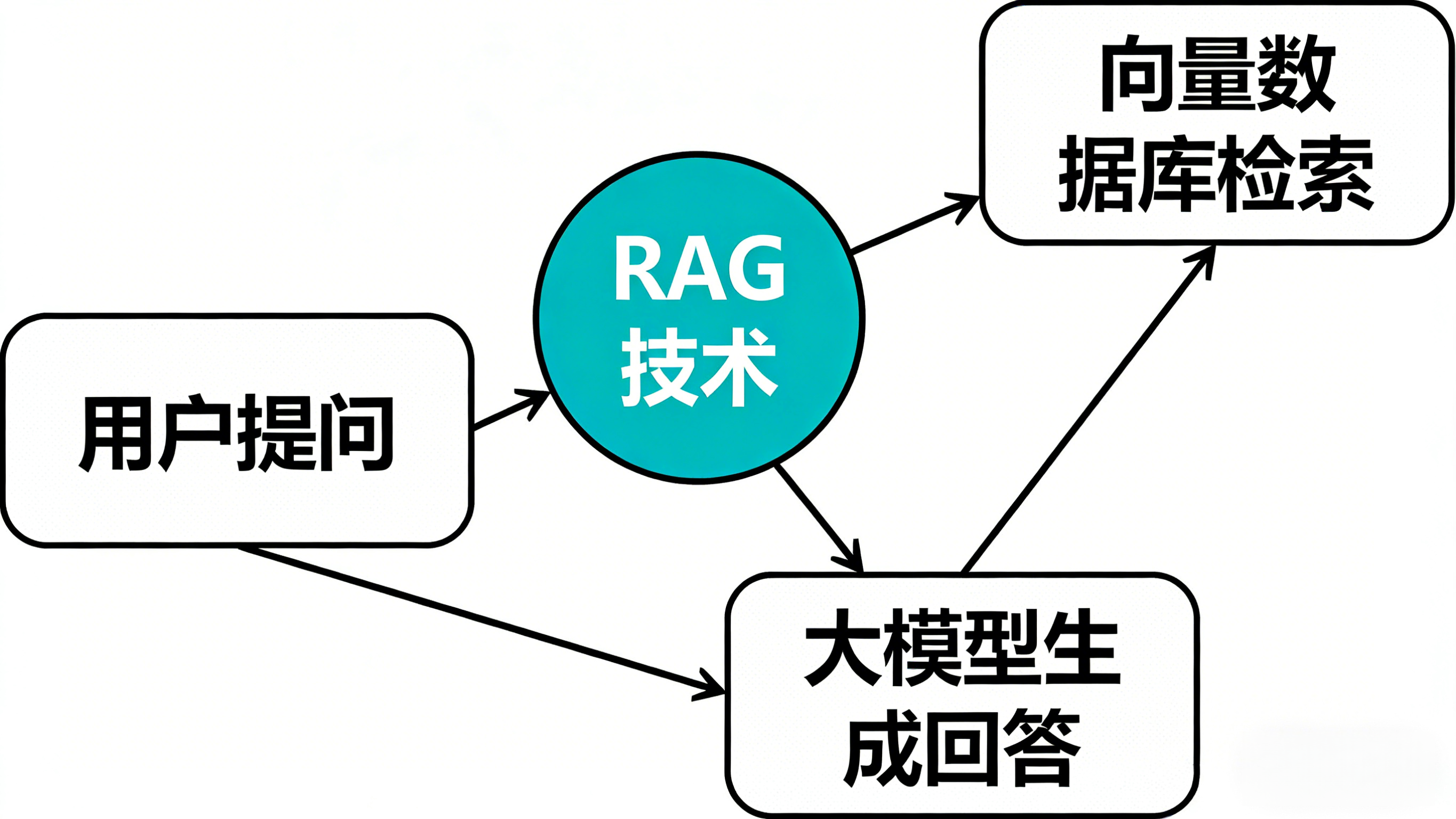 RAG 技术核心流程图.png
RAG 技术核心流程图.png
二、前置环境准备(5 分钟完成)
本教程全程采用轻量化工具,无需本地部署大模型,普通家用电脑即可完成,提前准备好以下环境即可:
基础环境:Python 3.9 及以上版本(官网直接下载安装即可)
核心工具:大模型 API(推荐使用豆包 API、OpenAI API,新手友好)、Chroma 轻量向量数据库(无需单独部署,Python 库直接调用)
依赖包安装:打开电脑终端,执行以下一行命令,即可一键安装所有所需依赖
pip install langchain chromadb python-docx pypdf openai tiktoken
 RAG 实战环境依赖安装成功示意图.png
RAG 实战环境依赖安装成功示意图.png
三、核心实战全流程(20 分钟落地)
以下代码全程带注释,可直接复制复用,仅需替换你的文档路径和 API 密钥即可。
步骤 1:文档加载与文本分块
这一步的核心是把你的私有文档(支持 PDF、Word、TXT 格式)加载进来,并切成合适大小的文本块,解决大模型上下文窗口限制,同时提升检索精度。
# 导入文档加载与分块工具
from langchain.document_loaders import PyPDFLoader, Docx2txtLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载你的私有文档,支持pdf、docx、txt格式,替换为你的文档路径
loader = PyPDFLoader("你的私有文档.pdf")
# 若为Word文档,使用:loader = Docx2txtLoader("你的文档.docx")
# 若为TXT文档,使用:loader = TextLoader("你的文档.txt")
documents = loader.load()
# 文本分块配置,新手直接使用默认参数即可
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 单块文本长度
chunk_overlap=50, # 块间重叠字符,避免内容断裂
separators=["\n\n", "\n", "。", " ", ""] # 分割优先级
)
# 完成文档分块
split_docs = text_splitter.split_documents(documents)步骤 2:构建向量数据库
这一步是 RAG 的核心,把分块的文本转换成向量数据,存入向量数据库,实现后续的语义检索,而非简单的关键词匹配。
# 导入向量数据库与embedding工具 from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import Chroma # 初始化embedding模型,替换为你的API密钥与地址 embedding = OpenAIEmbeddings( api_key="你的API_KEY", base_url="你的API接口地址" ) # 构建向量数据库,数据持久化到本地chroma_db文件夹 db = Chroma.from_documents( documents=split_docs, embedding=embedding, persist_directory="./chroma_db" ) # 保存数据库到本地 db.persist()
步骤 3:搭建检索问答链路
这一步将向量数据库检索与大模型生成结合,完成完整的问答链路,实现基于私有文档的精准回答
# 导入大模型与问答链工具
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# 初始化大模型,temperature=0让回答更严谨,减少幻觉
llm = ChatOpenAI(
model_name="gpt-3.5-turbo", # 可替换为豆包等其他大模型
api_key="你的API_KEY",
base_url="你的API接口地址",
temperature=0
)
# 构建检索问答链,检索Top3最相关的文档内容
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever(search_kwargs={"k": 3}),
return_source_documents=True
)
# 测试问答,替换为你的问题即可
result = qa_chain({"query": "请解释文档中XX功能的使用方法"})
print("AI精准回答:", result["result"])执行完以上代码,你就拥有了一个专属的 AI 知识库,无论是读书笔记答疑、产品手册查询、项目文档梳理,都能实现精准无幻觉的回答。
 个人 AI 知识库问答效果演示图.png
个人 AI 知识库问答效果演示图.png
四、效果调优 & 新手避坑指南
文本分块优化:专业文档建议 chunk_size 设为 800-1000,碎片化笔记建议设为 300-500,始终保留 50-100 的重叠字符,避免内容断裂
检索精度优化:默认检索 Top3 相关内容,若文档内容较长,可调整为 Top5,避免超出大模型上下文窗口
常见坑规避:文档加载前先清理乱码、空白页与无效内容;embedding 模型需与大模型适配,避免出现语义匹配偏差;API 密钥注意妥善保管,不要直接提交到公开代码库。
RAG 技术的落地场景远不止个人知识库,还可以拓展为企业客服机器人、行业知识问答系统、课程学习助手、产品售后答疑工具等。后续我们还会更新本地开源大模型接入、多模态文档支持、web 检索联动等进阶 AI 实战教程,带你从零到一掌握 AI 落地全流程。
来源:
互联网
本文观点不代表区块经立场,不承担法律责任,文章及观点也不构成任何投资意见。

评论列表