
前言
2026年,AI智能体(AI Agent)已经成为企业智能化转型的核心驱动力。从国电南瑞发布的企业级智能体平台"南瑞瑞元",到地平线即将推出的舱驾融合智能体芯片,再到Google Cloud在Next大会上力推的Agentic AI战略,智能体技术正在从实验室走向千行百业。
然而,对于开发者而言,如何从零开始构建一个真正可用的AI智能体,仍然是一个充满挑战的任务。本文将结合最新行业实践,详细讲解AI智能体开发的完整流程,帮助你掌握从需求分析到生产部署的全部关键环节。
 AI智能体开发流程
AI智能体开发流程
一、为什么需要系统化的智能体开发方法论
很多开发者在初接触智能体时,往往会陷入一个误区:将智能体简单理解为"大模型+提示词"的组合。这种理解在demo阶段或许够用,但一旦涉及到生产环境,就会暴露出无数问题:
要解决这些问题,需要一套系统化的开发方法论。本文将带你走过智能体开发的六个核心阶段,每个阶段都有明确的目标和验收标准。
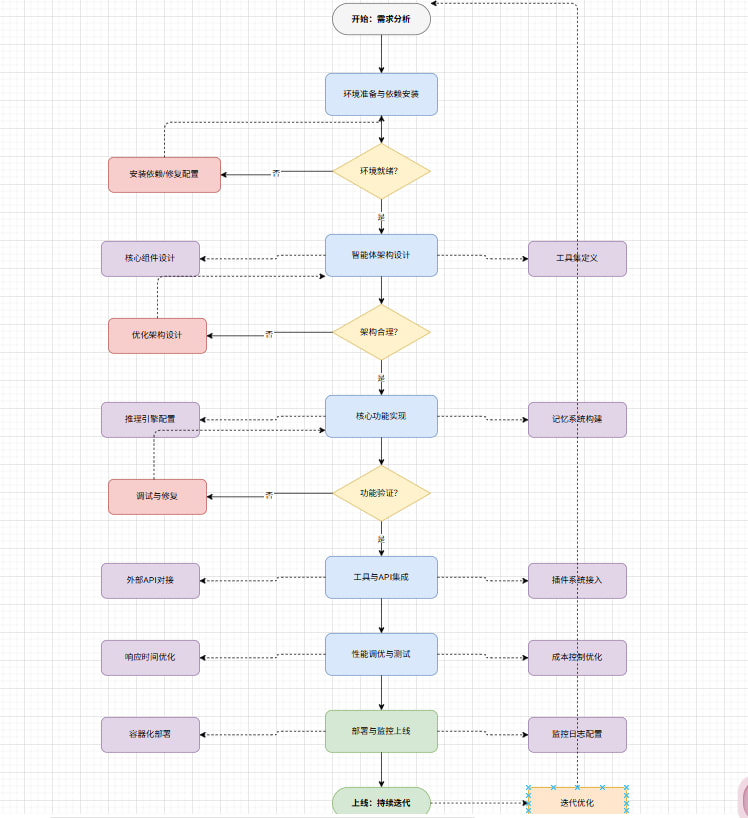 AI智能体开发流程图
AI智能体开发流程图
二、环境准备与依赖安装
2.1 基础环境配置
构建AI智能体的第一步是搭建稳定可靠的开发环境。这里推荐使用Python 3.10+作为运行时环境,并建议通过虚拟环境进行依赖管理:
# 创建虚拟环境 python -m venv agent-env source agent-env/bin/activate # Linux/Mac # agent-env\Scripts\activate # Windows # 核心依赖安装 pip install langchain langchain-openai langchain-community pip install python-dotenv # 环境变量管理 pip install sqlalchemy # 数据库连接 pip install redis # 缓存层
2.2 API密钥与配置管理
生产环境的API密钥绝不能硬编码在代码中。建议使用环境变量或专业的密钥管理服务:
from dotenv import load_dotenv
import os
load_dotenv() # 加载.env文件
# 获取API密钥
openai_api_key = os.getenv("OPENAI_API_KEY")
anthropic_api_key = os.getenv("ANTHROPIC_API_KEY")2.3 常见环境问题排查
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| API调用超时 | 网络问题或限流 | 检查代理配置,增加重试机制 |
| 模型响应质量差 | 温度参数设置不当 | 降低temperature至0.3-0.5 |
| 上下文溢出 | 累积token过多 | 实施消息截断策略 |
三、智能体架构设计
3.1 核心组件划分
一个完整的AI智能体通常包含以下核心组件:
推理引擎(Reasoning Engine):负责理解和生成自然语言,决定下一步行动。当前主流方案包括ReAct(推理+行动)、CoT(思维链)等模式。
记忆系统(Memory System):分为短期记忆(当前会话)和长期记忆(持久化存储)。短期记忆通常用滑动窗口实现,长期记忆则依赖向量数据库。
工具层(Tool Layer):智能体与外部世界交互的接口。每个工具都是一个可执行的函数或API调用。
规划器(Planner):将复杂任务分解为可执行的子任务序列。
3.2 架构模式选择
根据应用场景的不同,可以选择不同的架构模式:
单智能体架构:适用于任务相对简单、流程固定的场景。优点是实现简单、调试方便。
多智能体协作架构:适用于复杂任务的分解与协同。例如,一个智能体负责意图识别,另一个负责任务执行,再有一个负责结果验证。
分层架构:大型企业级应用通常采用分层设计,底层是基础设施层,中间是能力服务层,顶层是业务应用层。
3.3 架构设计评审清单
在完成架构设计后,建议从以下维度进行自检:
四、核心功能实现
4.1 推理引擎配置
以LangChain为例,配置一个基础的ReAct智能体:
from langchain.agents import AgentType, initialize_agent from langchain_openai import ChatOpenAI from langchain.tools import Tool from langchain import hub # 初始化大模型 llm = ChatOpenAI( model="gpt-4-turbo", temperature=0.3, max_tokens=2000 ) # 定义工具 def search_database(query: str) -> str: """搜索数据库中的相关信息""" # 实现搜索逻辑 return "搜索结果" tools = [ Tool( name="数据库搜索", func=search_database, description="当需要查询结构化数据时使用此工具" ) ] # 初始化智能体 agent = initialize_agent( tools=tools, llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT, verbose=True )
4.2 记忆系统构建
记忆系统是智能体"记得住"的关键。一个实用的方案是结合短期记忆和长期记忆:
from langchain.memory import ConversationBufferMemory from langchain_community.vectorstores import Chroma from langchain_openai import OpenAIEmbeddings class HybridMemory: def __init__(self): # 短期记忆:滑动窗口 self.short_term = ConversationBufferMemory( memory_key="chat_history", output_key="output", max_token_limit=2000 ) # 长期记忆:向量数据库 self.long_term = Chroma( persist_directory="./memory_db", embedding_function=OpenAIEmbeddings() ) def add_interaction(self, text: str): """添加交互记录到记忆""" # 添加到短期记忆 self.short_term.chat_memory.add_user_message(text) # 异步添加到长期记忆 self.long_term.add_texts([text]) def retrieve(self, query: str, top_k: int = 5): """检索相关记忆""" return self.long_term.similarity_search(query, k=top_k)
4.3 工具调用设计原则
工具是智能体能力的延伸。在设计工具时,需要注意:
职责单一:每个工具只做一件事,保持功能纯粹
描述清晰:工具的描述(description)会直接影响模型的调用决策,必须准确描述工具的用途和参数格式
错误处理:工具调用可能失败,需要定义清晰的错误码和错误信息
幂等性:在可能的情况下,使工具调用具有幂等性,方便重试和调试
五、工具与API集成
5.1 外部API对接
在实际应用中,智能体往往需要调用各种外部API。以下是一个典型的API集成模式:
import requests
from typing import Dict, Any
class APIClient:
def __init__(self, base_url: str, api_key: str):
self.base_url = base_url
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
def call_tool(self, endpoint: str, params: Dict[str, Any]) -> str:
try:
response = requests.post(
f"{self.base_url}/{endpoint}",
json=params,
headers=self.headers,
timeout=30
)
response.raise_for_status()
return response.json()
except requests.exceptions.Timeout:
return '{"error": "请求超时"}'
except requests.exceptions.RequestException as e:
return f'{{"error": "{str(e)}"}}'5.2 插件系统设计
为了让智能体具备更好的扩展性,建议设计一套插件机制
from abc import ABC, abstractmethod from typing import List class BasePlugin(ABC): @property @abstractmethod def name(self) -> str: pass @property @abstractmethod def description(self) -> str: pass @abstractmethod def execute(self, **kwargs) -> str: pass class PluginManager: def __init__(self): self._plugins: List[BasePlugin] = [] def register(self, plugin: BasePlugin): self._plugins.append(plugin) def get_tools(self) -> List[Tool]: return [ Tool( name=plugin.name, func=plugin.execute, description=plugin.description ) for plugin in self._plugins ]
六、性能调优与测试
6.1 响应时间优化
智能体的响应延迟直接影响用户体验。以下是几个关键优化点:
流式输出:启用流式输出(streaming)可以让用户更快看到首字响应:
from langchain_openai import ChatOpenAI llm = ChatOpenAI( model="gpt-4-turbo", streaming=True, callbacks=[ StreamingStdOutCallbackHandler() ] )
缓存策略:对于重复或相似的查询,使用缓存可以显著降低响应时间。可以使用Redis实现简单的查询缓存:
import hashlib import json def cached_call(func, query: str, ttl: int = 3600): cache_key = hashlib.md5(query.encode()).hexdigest() # 尝试从缓存获取 cached = redis.get(cache_key) if cached: return json.loads(cached) # 执行调用 result = func(query) # 存入缓存 redis.setex(cache_key, ttl, json.dumps(result)) return result
6.2 成本控制
大模型API调用是主要成本来源。以下策略可以有效控制成本:
精确的上下文截断:根据任务需求调整上下文窗口大小,避免不必要的token消耗
模型选择:简单任务使用更便宜的模型(如GPT-3.5-Turbo),复杂推理再使用高端模型
批处理:将可以并行处理的请求合并发送
6.3 测试用例设计
智能体的测试需要覆盖多种场景:
import pytest
def test_agent_basic_query():
"""测试基础查询功能"""
response = agent.run("今天北京的天气怎么样?")
assert "天气" in response.lower()
def test_agent_tool_calling():
"""测试工具调用"""
response = agent.run("帮我查询2024年GDP数据")
# 验证是否调用了数据查询工具
assert any(trace["tool"] == "database_search" for trace in agent.trace)
def test_agent_error_handling():
"""测试错误处理"""
response = agent.run("执行一个不存在的操作")
assert "无法" in response or "失败" in response七、部署与监控
7.1 容器化部署
将智能体应用容器化是现代部署的标准做法:
FROM python:3.10-slim WORKDIR /app COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . CMD ["gunicorn", "-w", "4", "-b", "0.0.0.0:8000", "app:app"]
7.2 监控与日志
生产环境的监控至关重要。建议关注以下指标:
业务指标:任务成功率、平均响应时间、用户满意度
技术指标:API调用成功率、错误率、资源使用率
成本指标:Token消耗、API费用
import logging
from prometheus_client import Counter, Histogram, generate_latest
# 定义指标
request_count = Counter('agent_requests_total', 'Total requests')
request_duration = Histogram('agent_request_duration_seconds', 'Request duration')
# 在请求处理中记录
@request_duration.time()
def handle_request(query: str):
request_count.inc()
# 处理逻辑...八、总结与展望
AI智能体开发是一个系统工程,需要开发者在架构设计、工程实现、运维监控等多个维度都具备扎实的能力。本文从环境准备、架构设计、核心实现、工具集成、性能优化到部署上线,详细讲解了智能体开发的完整流程。
随着大模型技术的持续演进和行业应用的深入,智能体的开发范式也在不断迭代。建议开发者在掌握本文所述基础方法的同时,持续关注行业最新动态,如Google Cloud在Agentic AI领域的最新实践,以及多模态智能体、具身智能等新兴方向。
记住,一个优秀的AI智能体不仅仅是技术堆砌,更是对用户需求的深刻理解和对产品体验的持续打磨。祝你在智能体开发的道路上有所收获!
来源:
互联网
本文观点不代表区块经立场,不承担法律责任,文章及观点也不构成任何投资意见。

评论列表